 ICML
ICML
ProAct: A Benchmark and Multimodal Framework for Structure-Aware Proactive Response
International Conference on Machine Learning (ICML), 2026.
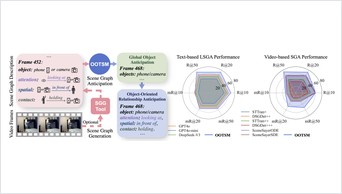
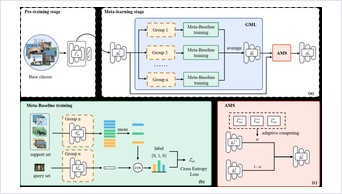
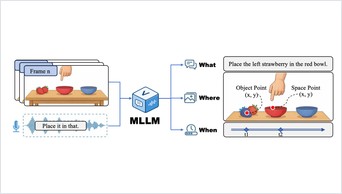
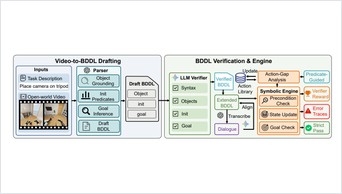
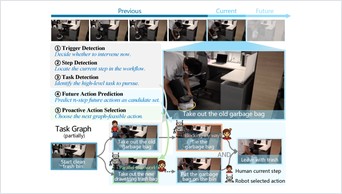
ProAct studies proactive embodied agents that continuously monitor video, decide when to intervene, and select actions under explicit task-graph constraints. The benchmark covers 75 tasks, 5,383 videos, and 91,581 step-level annotations.
@inproceedings{zhu2026proact,
title={ProAct: A Benchmark and Multimodal Framework for Structure-Aware Proactive Response},
author={Zhu, Xiaomeng and Zhu, F. and Zhou, W. and Tian, Y. and others},
booktitle={International Conference on Machine Learning},
year={2026}
}